






























减小包的体积,产品或运营同学认为,包体积越小,越能提高下载量
应用市场限制,如App Store、Google Play 都有相关包体积的规定,都是以更小为主
减少内存占用,不管是Rom还是Ram 肯定是随着应用包的体积增加而成正比增加,所以减小包体,也是在间接优化内存占用
我们找了这么几个原因,促使我们做这件事,确实在实际的工作中,特别是toC的小伙伴,更加明显,他们一直在做包体积的优化,那么要优化体积,那肯定是要知道包的构成,这样才能有合适的优化方法,那么我们再来看看包的构成。
包的构成分析
我们利用Android studio的可视化工具,打开了一个普通的apk安装包,如下
为了更有说服力,我拿了WX的包来分析看,如下:
通过两张图,我们分辨出包的大致构成如下:
Dex、so库。且WX的SO库只保留了armeabi-v7a架构的包,已占比50%,可见很高。
r资源文件及assets ,存放图片,音频,资源文件的位置
resources.arsc 文件也达到了6.8MB,这是资源索引表,开发中Resources就是通过resources.arsc把Resource的ID转化成资源文件的名称,然后交由AssetManager来加载的,它是由AAPT工具在打包过程中生成。
META-INF 签名信息
AndroidManifest.xml 清单配置文件
整体来看,占比较高的就是 Dex、So、r、assets、resources.arsc,那么我们优化,肯定是要从这几个方面入手对吧。
如何减小安装包的体积
1.资源压缩
对大图进行无损压缩,对不需要alpha通道的png图,压缩成jpg,或者使用更小的webp图片:webp介绍对于assets中存储的音频文件可以选择远程依赖,第一次下载后做缓存处理
2.通过编译器缩减,混淆
利用R8 编译器,进行代码缩减、资源缩减、混淆处理等,都可以有效的减小包体积,具体介绍请看:缩减、混淆处理和优化应用注意:R8编译器要求 Android Gradle 插件 3.4.0 或更高版本
3.resources.arsc文件缩减
这个文件怎么缩减呢?经过查询资料发现,该文件对于不同的语言,不同的编码格式有一定的影响,直接说结论:
对于纯英文来讲,建议使用utf-8格式编码
对于中文来讲,建议使用utf-16
具体实现操作请看: aapt 相关命令
4.so库精简
通过上面第二张图我们发现,wx的so库只保留了armeabi-v7a架构,这也是目前最流行的架构,wx这么大的用户量都敢只保留一个,你有啥不敢的。将x86、arm64-v8a果断删了吧。这是表面的优化,更深层次的就需要对so库代码精简,如:抽离独立的库,减少冗余代码。还有建议C++运行时库使用stlport_shared,同样可以减少包大小,且可以节省一点内存,这种方式请注意:应用程序需要先加载所需要的共享库,然后再加载依赖此共享库的其他原生模块
static{ System.loadLibrary("stlport_shared"); System.loadLibrary("xxxxx");}
5.Dex文件数量优化
在我们使用multiDex后,或者说方法数达到65535之后,不得不对代码进行分包,分包会带来什么问题呢?
method id 分配不合理导致更多的Dex量,由于method id 的大量冗余导致每个 Dex 真正可以放的 Class 变少。
信息存储冗余,因为每个dex中都存在调用的方法的详细信息,举个例子,如果一个class method被其他dex引用到的话就会导致 这个class不光是在自己的dex中存在方法信息,被引用到的dex中也存储了class的方法信息,这样造成冗余,冗余过多就会导致dex数量增加。
知道了问题如何解决呢?答案就是尽量让方法的引用都在同一个dex中,这样就可以减少冗余,减少dex的新增,目前最优解建议使用:Facebook 的一个开源编译工具ReDex,具体使用方法建议去看文档:github.com/facebook/re…,这里就不展开描述。
6.Dex压缩
小结
说了这么多的优化放法,如果想做到极致,肯定还有方法,但我们现在处于5G时代,大家还会对10M甚至说100M有感觉吗?这就需要于用户体验之间做一个权衡,一些极致的优化肯定是会降低用户体验的,需要按需而行吧。
Matrix App Checker
终于进入正题,我们了解了包的结构和常见的缩减方法,那么App Checker到底可以为我们提供什么样的帮助,来辅助我们进行缩减呢?随我一探究竟。
代码目录
exception目录中 抽象了两个 TaskExecuteException、TaskInitException异常,任务执行和任务初始化异常,方便捕获。
job目录中 抽象出 ApkJob 来管理所有的 Task 任务和 JobResult
output 目录 主要作用就是将输出的结果 以Json或者html格式的方式写入文件中
result 目录 对JobResult、TaskResult的抽象及相关实现
task 目录 所有任务的实现,包括 CountClassTask 统计类数量、MethodCountTask 统计方法量、UnzipTask 解压任务负责将apk解压成相关文件。
ApkChecker 负责创建Job,然后调用run方法。
类图
文字描述总显得有些乏力,画一下类结构图来帮助我们理解代码。
ApkChecker是检查启动类,负责创建出ApkJob,再由ApkJob创建出任务列表,通过Factory工厂模式创建出实际的任务对象,最后返回任务结果,大致就是这样,所以大致的流程图应该是这样。
细看源码
ApkChecker部分源码:
public final class ApkChecker { public static void main(String... args) { if (args.length > 0) { //创建出ApkChecker对象 ApkChecker m = new ApkChecker(); m.run(args); } else { System.out.println(INTRODUCT + HELP); System.exit(0); } } private void run(String[] args) { // 创建Job对象,调用run函数 ApkJob job = new ApkJob(args); try { job.run(); } catch (Exception e) { e.printStackTrace(); System.exit(-1); } }}
public void run() throws Exception { //解析参数,创建对应的task if (parseParams()) { //创建解压任务对apk进行解压操作 ApkTask unzipTask = TaskFactory.factory(TaskFactory.TASK_TYPE_UNZIP, jobConfig, new HashMap<String, String>()); // 将任务放入preTasks集合中 preTasks.add(unzipTask); //通过jobConfig获取 输出格式配置, for (String format : jobConfig.getOutputFormatList()) { //获取对应format的对象JobJsonResult或JobHtmlResult JobResult result = JobResultFactory.factory(format, jobConfig); if (result != null) { jobResults.add(result); } else { Log.w(TAG, "Unknown output format name '%s' !", format); } } //开始执行 execute(); } else { ApkChecker.printHelp(); } }// 该函数作用就是根据命令行传递的参数,创建对应的Task,最后将其放入taskList集合中 private boolean parseParams() { if (args != null && args.length >= 2) {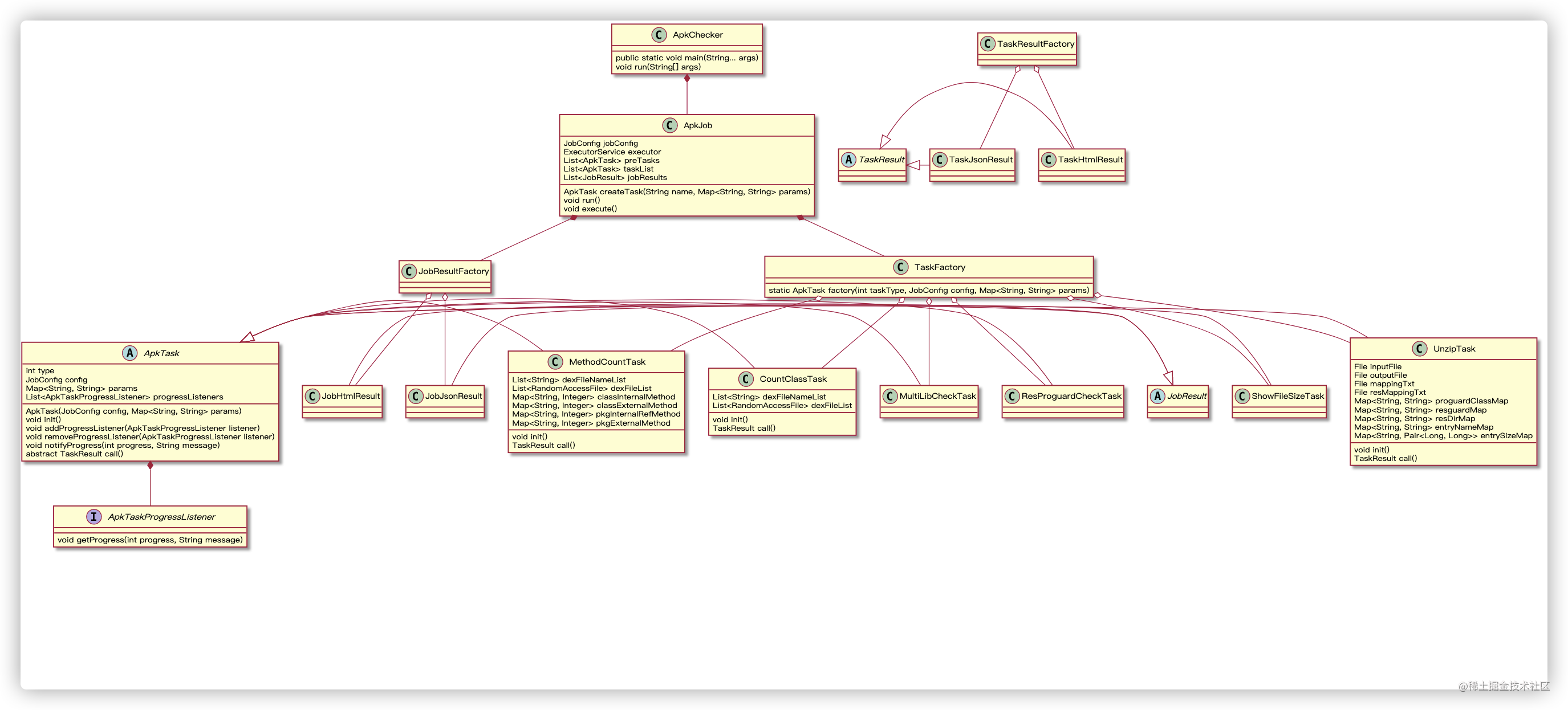 int paramLen = parseGlobalParams(); for (int i = paramLen; i < args.length; i++) { if (args[i].startsWith("-") && !args[i].startsWith("--")) { Map<String, String> params = new HashMap<>(); paramLen = parseParams(i + 1, args, params); if (!params.containsKey(JobConstants.PARAM_R_TXT)) { String inputDir = jobConfig.getInputDir(); if (!Util.isNullOrNil(inputDir)) { params.put(JobConstants.PARAM_R_TXT, inputDir + "/" + ApkConstants.DEFAULT_RTXT_FILENAME); } } ApkTask task = createTask(args[i], params); if (task != null) { taskList.add(task); } i += paramLen; } } } else { return false; } return true; }// 最后看执行的过程private void execute() throws Exception { try {//首先将 preTasks 准备中的任务 优先执行,然后将执行的结果 for (ApkTask preTask : preTasks) { //任务初始化 preTask.init(); //任务同步执行,并获取结果 TaskResult taskResult = preTask.call(); if (taskResult != null) { TaskResult formatResult = null; //遍历预先配置好的结果集 for (JobResult jobResult : jobResults) { //根据taskResult 与 jobResult 配置匹配结果 formatResult = TaskResultFactory.transferTaskResult(taskResult.taskType, taskResult, jobResult.getFormat(), jobConfig); if (formatResult != null) { //将解压的任务结果放到jobResult中 jobResult.addTaskResult(formatResult); } } } } //初始化其他任务 for (ApkTask task : taskList) { task.init(); } //解压缩还是同步执行,这里就用到了异步,创建一个线程池,通过代码发现,默认只有一个线程。 List<Future<TaskResult>> futures = executor.invokeAll(taskList, timeoutSeconds, TimeUnit.SECONDS); for (Future<TaskResult> future : futures) { //通过get同步获取返回结果,由于线程池只有一个线程,所以看似并发,其实这里并没有。 TaskResult taskResult = future.get(); if (taskResult != null) { TaskResult formatResult = null; for (JobResult jobResult : jobResults) { //同样匹配结果最终放入到jobResult中 formatResult = TaskResultFactory.transferTaskResult(taskResult.taskType, taskResult, jobResult.getFormat(), jobConfig); if (formatResult != null) { jobResult.addTaskResult(formatResult); } } } } //关闭线程池 executor.shutdownNow(); for (JobResult jobResult : jobResults) { //输出到文件中 jobResult.output(); } Log.d(TAG, "parse apk end, try to delete tmp un zip files"); //删除解压的apk文件目录 FileUtils.deleteDirectory(new File(jobConfig.getUnzipPath())); } catch (Exception e) { Log.e(TAG, "Task executor execute with error:" + e.getMessage()); throw e; } }
整个过程,其实很简单,并不复杂,整个流程走完了,我们缺不知,导致任务执行了什么样子的代码,才能获取到相应的信息呢?我们来看几个具体的Task任务
MethodCountTask
为什么选择方法计数呢?因为我们经常会遇到项目方法数量统计需求,到底是如何统计的呢?我们是不是可以借助这次的学习就可以搞定了?随我来。直接上源码
//首先看下初始化方法,都做了哪些事情。 @Override public void init() throws TaskInitException { super.init(); // 获取解压后的apk文件目录 String inputPath = config.getUnzipPath(); if (Util.isNullOrNil(inputPath)) { throw new TaskInitException(TAG + "---APK-UNZIP-PATH can not be null!"); } Log.i(TAG, "input path:%s", inputPath); // 根据路创建File对象,检查文件的属性,看是否匹配规则 inputFile = new File(inputPath); if (!inputFile.exists()) { throw new TaskInitException(TAG + "---APK-UNZIP-PATH '" + inputPath + "' is not exist!"); } else if (!inputFile.isDirectory()) { throw new TaskInitException(TAG + "---APK-UNZIP-PATH '" + inputPath + "' is not directory!"); } // 如果匹配规则,就找到文件夹下的所有文件 File[] files = inputFile.listFiles(); try { if (files != null) { for (File file : files) { //找到dex结尾的文件 if (file.isFile() && file.getName().endsWith(ApkConstants.DEX_FILE_SUFFIX)) { // 加入到dexFileNameList列表缓存中 dexFileNameList.add(file.getName()); //RandomAccessFile是Java中输入,输出流体系中功能最丰富的文件内容访问类 //它提供很多方法来操作文件,包括读写支持 //与普通的IO流相比,它最大的特别之处就是支持任意访问的方式,程序可以直接跳到任意地方来读写数据。 RandomAccessFile randomAccessFile = new RandomAccessFile(file, "rw"); //随机文件对象加入到dexFileList中 dexFileList.add(randomAccessFile); } } } } catch (FileNotFoundException e) { throw new TaskInitException(e.getMessage(), e); } //获取配置信息,目的是为了分组,是按类 class 或者按包 package if (params.containsKey(JobConstants.PARAM_GROUP)) { if (JobConstants.GROUP_PACKAGE.equals(params.get(JobConstants.PARAM_GROUP))) { group = JobConstants.GROUP_PACKAGE; } else if (JobConstants.GROUP_CLASS.equals(params.get(JobConstants.PARAM_GROUP))) { group = JobConstants.GROUP_CLASS; } else { Log.e(TAG, "GROUP-BY '" + params.get(JobConstants.PARAM_GROUP) + "' is not correct!"); } } }
countDex(dexFile) 函数分析
private void countDex(RandomAccessFile dexFile) throws IOException { //按类分组的,内部方法Map,清除掉缓存 classInternalMethod.clear(); //按类分组的,外部依赖方法Map,清除掉缓存 classExternalMethod.clear(); //按包分组的,同上 pkgInternalRefMethod.clear(); pkgExternalMethod.clear(); //使用的com.android.dexdeps 包下的DexData类, DexData dexData = new DexData(dexFile); dexData.load(); //获取所有方法索引对象,包括内部方法和外部索引的方法 MethodRef[] methodRefs = dexData.getMethodRefs(); //获取所有外部类的索引数据 ClassRef[] externalClassRefs = dexData.getExternalReferences(); //获取混淆过的类 Map<String, String> proguardClassMap = config.getProguardClassMap(); String className = null; for (ClassRef classRef : externalClassRefs) { //获取类名 className = ApkUtil.getNormalClassName(classRef.getName()); if (proguardClassMap.containsKey(className)) { //匹配并赋值为混淆前的类名 className = proguardClassMap.get(className); } if (className.indexOf('.') == -1) { continue; } //将类名放入到外部方法Map中,供下面匹配外部方法时使用 classExternalMethod.put(className, 0); } //遍历所有方法,找到外部和内部方法,并分别加入到classExternalMethod、classInternalMethod Map中 for (MethodRef methodRef : methodRefs) { //获取该方法的类名 className = ApkUtil.getNormalClassName(methodRef.getDeclClassName()); //匹配混淆前的类名 if (proguardClassMap.containsKey(className)) { className = proguardClassMap.get(className); } if (!Util.isNullOrNil(className)) { if (className.indexOf('.') == -1) { continue; } //根据类名和外部方法存储的类信息匹配,匹配上就说明是外部方法引用。 if (classExternalMethod.containsKey(className)) { classExternalMethod.put(className, classExternalMethod.get(className) + 1); } else if (classInternalMethod.containsKey(className)) { classInternalMethod.put(className, classInternalMethod.get(className) + 1); } else { classInternalMethod.put(className, 1); } } } //删除没有方法引用的类 Iterator<String> iterator = classExternalMethod.keySet().iterator(); while (iterator.hasNext()) { if (classExternalMethod.get(iterator.next()) == 0) { iterator.remove(); } } }
通过源码的分析,其实原理就是使用DexData对象加载dexFile,最后getMethodRefs、getExternalReferences方法获取相关信息,最后通过外部的classExternalMethod 将所有的方法分类成内部方法和外部方法集合。
CountClassTask
经过上面的分析经验,我们再分析CountClassTask就简单了许多,直接找到核心代码如下:
DexData dexData = new DexData(dexFile);dexData.load();dexFile.close();ClassRef[] defClassRefs = dexData.getInternalReferences();Set<String> classNameSet = new HashSet<>();for (ClassRef classRef : defClassRefs) { String className = ApkUtil.getNormalClassName(classRef.getName()); if (classProguardMap.containsKey(className)) { className = classProguardMap.get(className); } if (className.indexOf('.') == -1) { continue; } classNameSet.add(className);}
上面使用了getExternalReferences,而这里直接使用getInternalReferences,获取所有内部类的索引数据,最终加入到一个HashSet中。整个过程简单明了。难道所有的Task的实现都是用到DexData对象处理的吗?并不是,我们来看下一个
UnusedAssetsTask
看类名,简单解释为未被使用的资源任务,其实就是找到assets文件夹下没有被依赖的资源,知道该任务的目的后,我们就来看看,它是如何实现的,先看下init中都做了什么准备
//初始化方法@Override public void init() throws TaskInitException { super.init();//先拿到解压后的apk文件路径 String inputPath = config.getUnzipPath(); if (Util.isNullOrNil(inputPath)) { throw new TaskInitException(TAG + "---APK-UNZIP-PATH can not be null!"); } inputFile = new File(inputPath); //同样的检测文件是否存在和检查文件的属性是否是文件夹 if (!inputFile.exists()) { throw new TaskInitException(TAG + "---APK-UNZIP-PATH '" + inputPath + "' is not exist!"); } else if (!inputFile.isDirectory()) { throw new TaskInitException(TAG + "---APK-UNZIP-PATH '" + inputPath + "' is not directory!"); } //根据配置文件中忽略资源列表,放入到ignoreSet中,为了忽略一些文件的检查,比如确定资源是有用的,就不需要被检查,缩小范围。 if (params.containsKey(JobConstants.PARAM_IGNORE_ASSETS_LIST) && !Util.isNullOrNil(params.get(JobConstants.PARAM_IGNORE_ASSETS_LIST))) { String[] ignoreAssets = params.get(JobConstants.PARAM_IGNORE_ASSETS_LIST).split(","); Log.i(TAG, "ignore assets %d", ignoreAssets.length); for (String ignore : ignoreAssets) { ignoreSet.add(Util.globToRegexp(ignore)); } } File[] files = inputFile.listFiles(); if (files != null) { for (File file : files) { if (file.isFile() && file.getName().endsWith(ApkConstants.DEX_FILE_SUFFIX)) { //同样的将dex文件,筛选出来,放入到dexFileNameList中 dexFileNameList.add(file.getName()); } } } }
初始化中,执行了常规的文件检查,params参数的整理,再将dex文件缓存到一个list中,待处理,再来看下call函数,看它如何找到了未被依赖资源。
小结
















用户评论
对于 Matrix 源码分析系列中的这一内容,《如何解析应用安装包》,我深感这既是一部技术指南,同时又充满了探究精神。这篇文章不仅详细介绍了解析过程,还从理论到实践,一步一步带你揭开应用安装包的秘密。
有11位网友表示赞同!
作为一个游戏玩家转技术人员的尝试者,读完《矩阵源码分析》中的“解析应用安装包”,感觉自己打开了新世界的大门。里面的内容深入浅出,将复杂技术知识化繁为简,非常适合初学者入门。
有6位网友表示赞同!
对于《Matrix源码系列之如何解析应用包》,我最看重的是作者不仅分享了具体的技术细节,还解释了为什么要这样做以及背后的设计理念和逻辑推理过程,这让我能够理解为何这样选择,并非是单纯复述代码流程而已。
有19位网友表示赞同!
在读《矩阵源码分析》的“安装包解析”部分时,我被其严谨的结构所吸引。从文件格式开始讲解到具体的解压、提取过程,每一步都解释得清晰透彻,适合喜欢自动手实践解析过程的玩家们。
有6位网友表示赞同!
《解析应用安装包》系列中的Matrix分析让我了解到技术文档编写的艺术性在于清晰表达和深入浅出。读完这一篇后,我发现自己对软件如何在底层运行有了更深的理解。
有19位网友表示赞同!
"如何使用矩阵视角解析应用安装包"这篇文章为我对软件开发的理解添砖加瓦。通过详实的数据实例解读,它帮我构建起一层关于软件启动与执行机制的认知桥梁。
有5位网友表示赞同!
读《Matrix源码系列分析》中的解析应用安装包部分时,发现作者不仅关注技术细节的精确性,还思考了这些知识在教学和实际工程项目中的应用和推广,让我受益匪浅。
有15位网友表示赞同!
"解析应用安装包"这篇文章给我提供了一个很好的角度去审视软件开发的过程。通过Matrix源码分析系列,我能够更深入地理解一个软件在计算机上运行的每一个步骤如何被封装成安装包。
有14位网友表示赞同!
对于像我这样的技术爱好者来说,《矩阵源码分析》中的“应用安装包解析”章节是一次知识之旅的好起点。其简洁明了的语言和实践导向的内容帮助我在短时间内理解了一个复杂主题的核心概念。
有17位网友表示赞同!
"Matrix之如何解析应用安装包"的系列文章帮助我打破了一种误解——以为技术学习只能通过枯燥的文字理解完成。图文并茂,代码示例丰富,让我在阅读时能更好地跟上步骤与分析。
有16位网友表示赞同!
这篇文章《矩阵源码深入解析应用安装包》彻底重塑了我对于应用构建和发布流程的认知。每一步细节都解释得那么好,让人能够感受到作者对技术的热爱。
有10位网友表示赞同!
"Matrix系列之解析应用安装包"是我最近的技术学习宝藏。文中大量的实例使我能够实际操作起来,并且理解到为何这些过程是必要的。
有17位网友表示赞同!
在读完《矩阵源码分析》中这篇关于解析器的文章后,我更加认识到细节在开发中的重要性。每个逻辑分支、错误处理机制都是构建稳健应用的关键。
有19位网友表示赞同!
这篇文章的标题就勾起了我的兴趣,《矩阵源码系列分析——如何解析应用安装包》让我体验了一次从表层到深层次的技术探索之旅。对初学者极友好,同时也能让资深开发者回炉加深理解。
有19位网友表示赞同!
《Matrix源码分析》中的“如何解析应用安装包”对我来说是一次思维觉醒的过程。通过实际操作代码并与理论知识对比,我感觉自己的编程技能和逻辑思考都得到了显著提升。
有5位网友表示赞同!